
每日新聞(爬取新聞)
v1.1 免費版- 軟件大小:13.6 MB
- 軟件語言:簡體中文
- 更新時間:2023-03-07
- 軟件類型:國產(chǎn)軟件 / 信息管理
- 運行環(huán)境:WinXP, Win7, Win8, Win10, WinAll
- 軟件授權(quán):免費軟件
- 官方主頁:
- 軟件等級 :
- 介紹說明
- 下載地址
- 精品推薦
- 相關(guān)軟件
- 網(wǎng)友評論
每日新聞軟件可以幫助用戶通過python爬蟲回去最新的新聞,每天的頭條新聞都可以直接在軟件上獲取,方便用戶查看今天有哪些熱門的頭條,軟件可以自動抓取新聞網(wǎng)站的頭條信息,直接將標(biāo)題顯示在抓取結(jié)果界面,方便用戶閱讀標(biāo)題內(nèi)容,標(biāo)題都是可以復(fù)制的,如果對新聞內(nèi)容感興趣就可以將其復(fù)制到瀏覽器搜索,方便閱讀詳細(xì)的新聞內(nèi)容,這款python爬蟲抓取新聞軟件很好用,適合經(jīng)常使用電腦工作,經(jīng)常查看新聞的朋友使用!
開發(fā)介紹
1 新聞源列表
本文要實現(xiàn)的異步爬蟲是一個定向抓取新聞網(wǎng)站的爬蟲,所以就需要管理一個定向源列表,這個源列表記錄了很多我們想要抓取的新聞網(wǎng)站的url,這些url指向的網(wǎng)頁叫做hub網(wǎng)頁,它們有如下特點:
它們是網(wǎng)站首頁、頻道首頁、最新列表等等;
它們包含非常多的新聞頁面的鏈接;
它們經(jīng)常被網(wǎng)站更新,以包含最新的新聞鏈接;
它們不是包含新聞內(nèi)容的新聞頁面;
Hub網(wǎng)頁就是爬蟲抓取的起點,爬蟲從中提取新聞頁面的鏈接再進(jìn)行抓取。Hub網(wǎng)址可以保存在mysql數(shù)據(jù)庫中,運維可以隨時添加、刪除這個列表;爬蟲定時讀取這個列表來更新定向抓取的任務(wù)。這就需要爬蟲中有一個循環(huán)來定時讀取hub網(wǎng)址。
2 網(wǎng)址池
異步爬蟲的所有流程不能單單用一個循環(huán)來完成,它是多個循環(huán)(至少兩個)相互作用共同完成的。它們相互作用的橋梁就是“網(wǎng)址池”(用asyncio.Queue來實現(xiàn))。
這個網(wǎng)址池就是我們比較熟悉的“生產(chǎn)者-消費者”模式。
一方面,hub網(wǎng)址隔段時間就要進(jìn)入網(wǎng)址池,爬蟲從網(wǎng)頁提取到的新聞鏈接也有進(jìn)入到網(wǎng)址池,這是生產(chǎn)網(wǎng)址的過程;
另一方面,爬蟲要從網(wǎng)址池中取出網(wǎng)址進(jìn)行下載,這個過程是消費過程;
兩個過程相互配合,就有url不斷的進(jìn)進(jìn)出出網(wǎng)址池。
3 數(shù)據(jù)庫
這里面用到了兩個數(shù)據(jù)庫:MySQL和Leveldb。前者用于保存hub網(wǎng)址、下載的網(wǎng)頁;后者用于存儲所有url的狀態(tài)(是否抓取成功)。
從網(wǎng)頁提取到的很多鏈接可能已經(jīng)被抓取過了,就不必再進(jìn)行抓取,所以他們在進(jìn)入網(wǎng)址池前就要被檢查一下,通過leveldb可以快速查看其狀態(tài)。
3. 異步爬蟲的實現(xiàn)細(xì)節(jié)
前面的爬蟲流程中提到兩個循環(huán):
循環(huán)一:定時更新hub網(wǎng)站列表
async defloop_get_urls(self,):print('loop_get_urls() start')while 1:
await self.get_urls()#從MySQL讀取hub列表并將hub url放入queue
await asyncio.sleep(50)
循環(huán)二: 抓取網(wǎng)頁的循環(huán)
async defloop_crawl(self,):print('loop_crawl() start')
last_rating_time=time.time()
asyncio.ensure_future(self.loop_get_urls())
counter=0while 1:
item=await self.queue.get()
url, ishub=item
self._workers+= 1counter+= 1asyncio.ensure_future(self.process(url, ishub))
span= time.time() -last_rating_timeif span > 3:
rate= counter /spanprint('tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time=time.time()
counter=0if self._workers >self.workers_max:print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
軟件功能
1、可以通過這款軟件獲取全部新聞內(nèi)容,軟件已經(jīng)配置地址池
2、可以自動識別全部新聞,可以將頭條新聞標(biāo)題抓取到軟件
3、通過python爬蟲快速捕捉新聞,每天打開軟件都可以知道新聞
4、如果你比較喜歡看新聞內(nèi)容,可以直接在這款軟件爬取標(biāo)題
軟件特色
1、軟件操作簡單,全部內(nèi)容都已經(jīng)編譯到EXE,啟動軟件就可以直接使用
2、讓用戶在軟件上知道今天有哪些新聞是熱門的
3、抓取的新聞標(biāo)題可以直接復(fù)制使用,方便到瀏覽器搜索新聞
4、每天上班打開電腦的時候就可以啟動這款軟件獲取今日新聞
使用方法
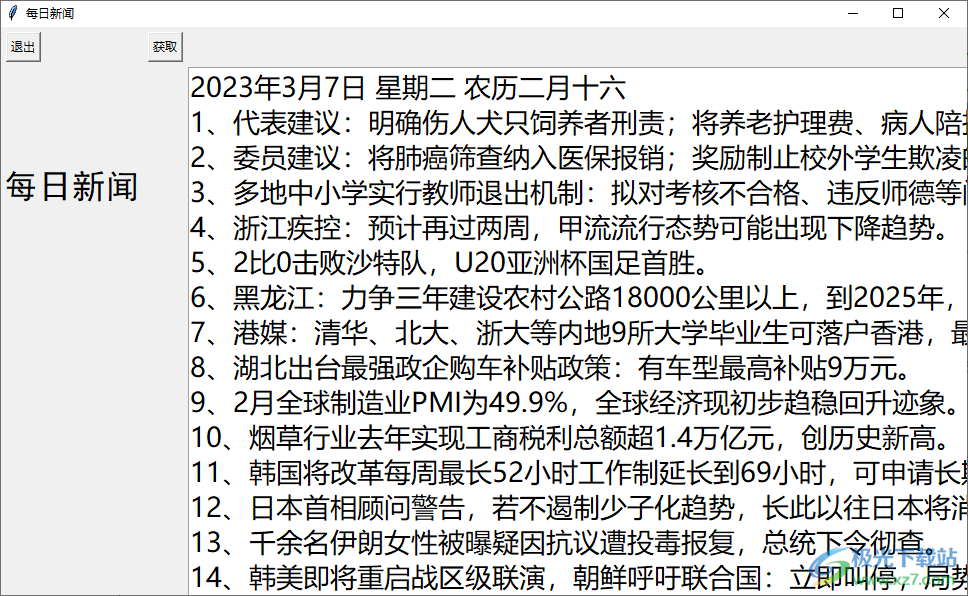
1、打開每日新聞軟件,點擊獲取按鈕就可以直接將新聞獲取

2、如圖所示,在軟件界面顯示全部新聞內(nèi)容,代表建議:明確傷人犬只飼養(yǎng)者刑責(zé),可以閱讀標(biāo)題
3、可以將感興趣的標(biāo)題復(fù)制到瀏覽器搜索新聞內(nèi)容,如果不感興趣就可以直接關(guān)閉軟件
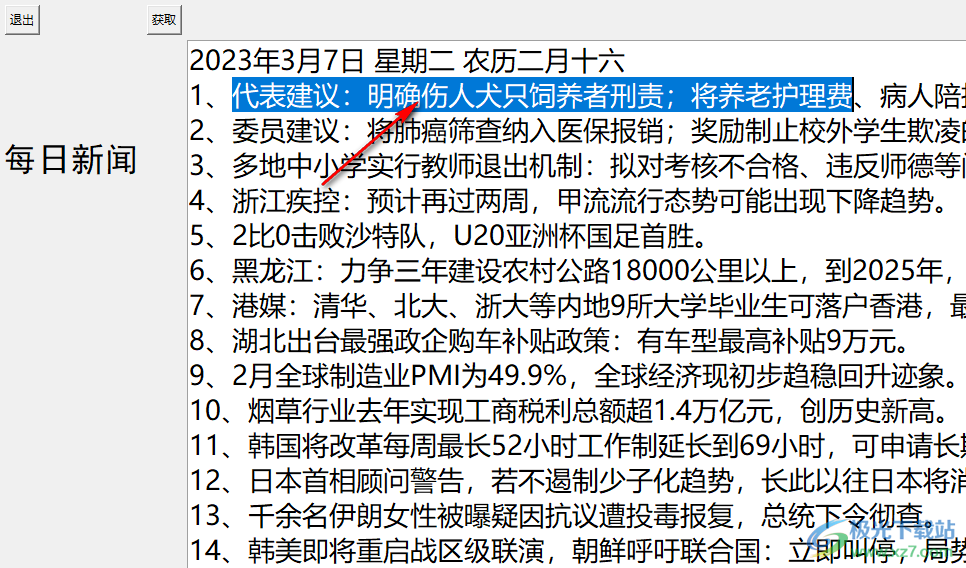
4、軟件獲取的新聞都是每天更新的,讓用戶可以快速抓取新聞網(wǎng)站每天的熱門內(nèi)容

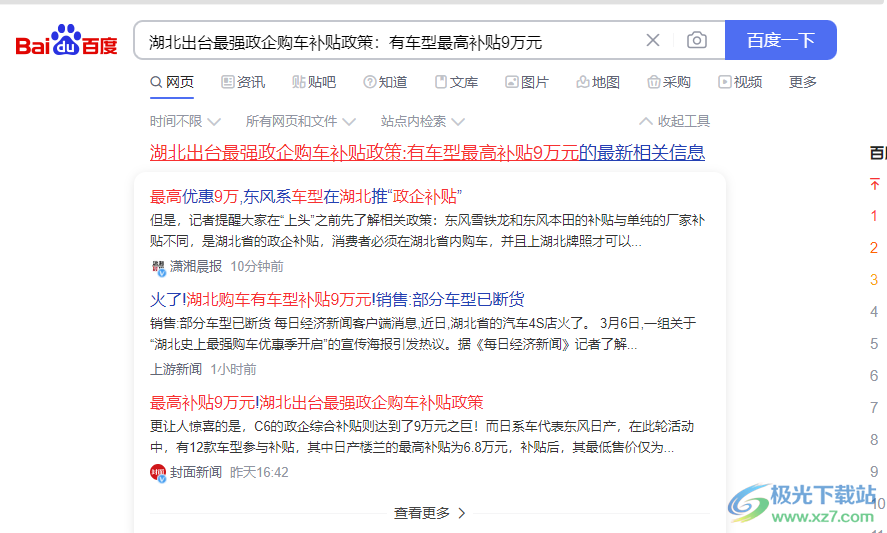
5、任意抓取到的內(nèi)容都可以點擊Ctrl+C復(fù)制使用,可以到瀏覽器查看新聞內(nèi)容

6、直接查詢新聞,點擊搜索到的新聞就可以查看詳細(xì)報告,如果你喜歡看新聞就可以下載使用
下載地址
- Pc版
每日新聞(爬取新聞) v1.1 免費版
本類排名
- 1 Liberty Street CurrencyManagev24.0.0.0 免費版
- 2 易特通訊錄軟件免費版v1.1 pc版
- 3 故事家軟件FunWorldv1.31 綠色版
- 4 思維導(dǎo)圖軟件MindMaster免費版v10.7.1.212
- 5 桌面透明便簽軟件v1.0.0.0 綠色版
- 6 商業(yè)思維導(dǎo)圖軟件XMind 8 Update 7VR3.7.9
- 7 Hex Editor Neo Ultimate Edition(進(jìn)制編輯器)v6.20.01
- 8 中國執(zhí)行信息公開網(wǎng)電腦版v1.0 官方版
- 9 天眼查pc版v12.22.1 最新版
- 10 thebrain 9 中文版v9.0.205.0 電腦版
本類推薦
- 1 XMind: ZEN思維導(dǎo)圖軟件v24.10.01101
- 2 商業(yè)思維導(dǎo)圖軟件XMind 8 Update 7VR3.7.9
- 3 藍(lán)牛it管理系統(tǒng)軟件v1.1 綠色版
- 4 智能一卡多表管理系統(tǒng)pc端v5.1.0 電腦版
- 5 小海精巧通訊錄官方版v3.0 大眾版
- 6 易特通訊錄軟件免費版v1.1 pc版
- 7 myexcel.net(網(wǎng)絡(luò)excel平臺)v3.5.1 官方版
- 8 小蝌蚪生日提醒企業(yè)版v5.2 最新版
- 9 天涯人脈通訊錄最新版v3.4.45.0 官方版
- 10 中國執(zhí)行信息公開網(wǎng)電腦版v1.0 官方版










裝機必備
換一批























- 聊天
- qq電腦版
- 微信電腦版
- yy語音
- skype
- 視頻
- 騰訊視頻
- 愛奇藝
- 優(yōu)酷視頻
- 芒果tv
- 剪輯
- 愛剪輯
- 剪映
- 會聲會影
- adobe premiere
- 音樂
- qq音樂
- 網(wǎng)易云音樂
- 酷狗音樂
- 酷我音樂
- 瀏覽器
- 360瀏覽器
- 谷歌瀏覽器
- 火狐瀏覽器
- ie瀏覽器
- 辦公
- 釘釘
- 企業(yè)微信
- wps
- office
- 輸入法
- 搜狗輸入法
- qq輸入法
- 五筆輸入法
- 訊飛輸入法
- 壓縮
- 360壓縮
- winrar
- winzip
- 7z解壓軟件
- 翻譯
- 谷歌翻譯
- 百度翻譯
- 金山翻譯
- 英譯漢軟件
- 殺毒
- 360殺毒
- 360安全衛(wèi)士
- 火絨軟件
- 騰訊電腦管家
- p圖
- 美圖秀秀
- photoshop
- 光影魔術(shù)手
- lightroom
- 編程
- python
- c語言軟件
- java開發(fā)工具
- vc6.0
- 網(wǎng)盤
- 百度網(wǎng)盤
- 阿里云盤
- 115網(wǎng)盤
- 天翼云盤
- 下載
- 迅雷
- qq旋風(fēng)
- 電驢
- utorrent
- 證券
- 華泰證券
- 廣發(fā)證券
- 方正證券
- 西南證券
- 郵箱
- qq郵箱
- outlook
- 阿里郵箱
- icloud
- 驅(qū)動
- 驅(qū)動精靈
- 驅(qū)動人生
- 網(wǎng)卡驅(qū)動
- 打印機驅(qū)動



網(wǎng)友評論